
”java 大数据 flink 流计算“ 的搜索结果

Flink 核心是一个流式的数据流执行引擎,其针对数据流的分布式计算提供了数据分布、数 据通信以及容错机制等功能。基于流执行引擎,Flink 提供了诸多更高抽象层的 API 以便用户编 写分布式任务:DataSet API, 对...
作为新一代大数据流处理框架,由于非常好的实时性,Flink独树一帜,在近些年引起了业内极大的兴趣和关注。Flink能够提供毫秒级别的延迟,同时保证了数据处理的低延迟、高吞吐和结果的正确性,还提供了丰富的时间类型...
Flink学习笔记
相反,事件驱动型应用是基于状态化流处理来完成,数据和计算不会分离,应用只需访问本地(内存或磁盘)即可获取数据。系统容错性的实现依赖于定期向远程持久化存储写入 checkpoint。下图描述了传统应用和事件驱动型...
flink 基于 Kafka 进行通讯的案例介绍,包括序列化、条件判定等。
flink-jobs为基于Flink的Java应用程序提供快速集成的能力,可通过继承FlinkJobsRunner快速构建基于Java的Flink流批一体应用程序,实现异构数据库实时同步和ETL。flink-jobs提供了数据源管理模块,通过flink-jobs运行...
这篇文章主要介绍了java大数据和python人工智能哪个好,具有一定借鉴价值,需要的朋友可以参考下。希望大家阅读完这篇文章后大有收获,下面让小编带着大家一起了解一下。随着大数据的不断涌现,处理大数据的技术也...

以计算每个 mid 出现的次数为例,keyby 之前,使用 flatMap 实现 LocalKeyby 功能//Checkpoint 时为了保证 Exactly Once,将 buffer 中的数据保存到该 ListState 中//本地 buffer,存放 local 端缓存的 mid 的 count...
flink是一个分布式计算/处理引擎,用于对无界和有界数据流进行状态计算。flink处理流程电商销售:实时报表、广告投放、实时推荐物联网:实时数据采集、实时报警物流配送、服务:订单状态跟踪、信息推送银行、金融:...
人们经常会问 Flink 是...它只凭借数据流引擎,就可以从容地应对背压。在这篇博文中,我们介绍一下背压。然后,我们深入了解 Flink 运行时如何在任务之间传送缓冲区中的数据。 最终,我们通过一个小实验展示这一点。

一.前言 二.概念 三.程序 四.运行
Apache Flink是一个开源的流式数据处理框架,支持高性能、可扩展、容错的分布式流处理应用。
大数据技术Flink架构
标签: flink
Apache Flink 是第三代分布式流处理器,它拥有极富竞争力的功能。它提供准确的大规模流处理,具有高吞吐量和低延迟。特别的是,以下功能使 Flink 脱颖而出:事件时间(event-time)和处理时间(processing-tme)语义...

Flink是一个对有界和无界数据流进行有状态计算的分布式处理引擎和框架,既可以处理有界的批量数据集,也可以处理无界的实时流数据,为批处理和流处理提供了统一编程模型,其代码主要由 Java 实现,部分代码由 Scala...
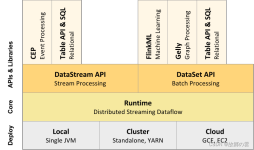


Apache Flink 是一个框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计算。Flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。





推荐文章
- YOLO V8车辆行人识别_yolov8 无法识别路边行人-程序员宅基地
- jpa mysql分页_Spring Boot之JPA分页-程序员宅基地
- win10打印图片中间空白以及选择打印机预览重启_win10更新后打印图片中间空白-程序员宅基地
- 【加密】SHA256加盐加密_sha256随机盐加密-程序员宅基地
- cordys 启动流程_cordys服务重启-程序员宅基地
- net中 DLL、GAC-程序员宅基地
- (一看就会)Visual Studio设置字体大小_visual studio怎么调整字体大小-程序员宅基地
- Linux中如何读写硬盘(或Virtual Disk)上指定物理扇区_dd写入确定扇区-程序员宅基地
- python【力扣LeetCode算法题库】面试题 17.16- 按摩师(DP)_一个有名的讲师,预约一小时为单位,每次预约服务之间要有休息时间,给定一个预约请-程序员宅基地
- 进制的转换技巧_10111100b转换为十进制-程序员宅基地